
2.4.1 统计
如果将对的问题与对的数据结合,简单的数数也会很有趣。 尽管社会学研究是用很复杂的语言表达的,很多社会研究仅仅是在统计一些事物。在大数据时代,数数变得更简单了,但这并不代表研究者可以脸滚键盘。相反,研究者应该思考:哪些事情是值得统计的?这看上去是个完全主观的问题,但还是有些一般规律。
总有一些学生说:我要数一数以前没人数过的东西,以此来激励他们的研究。例如,一个学生也许会说,有很多人研究过移民,也有很多人研究过双胞胎,但是没人研究过移民的双胞胎。我把这种策略称为 空洞驱动法, 这通常不是一条康庄大道。空洞驱动法就像是说,看那有个空洞,我来努力填满它。但并不是所有的洞洞都需要被填满。
不使用空洞驱动法,我认为更好的策略是关注一些 重要(important) 或 有趣(interesting) (最好两者兼有)的研究问题。这两个方面都有些难定义,但一种观点是,对政策制定者的重大决定有影响的可测量指标是重要的研究。例如,测量失业率就很重要,因为经济情况会影响政策的制定,而失业率是经济情况的风向标。通常来说,我认为研究者对重要性的都很有感觉。因此,剩下的部分,我将讲述两个有趣的数数型研究的例子。在例子中,研究者没有胡乱数数,而是用巧妙的设计来揭示重要的社会系统工作的一般规律。换句话说,使数数变有趣的,很多不是因为数据本身,而是来自这些一般规律。
第一个显示数数的简单且强力的例子是 Henry Farber(2015)的研究,他研究了纽约市出租车司机的行为。尽管这个研究对象乍看起来并不有趣,但这是一个 战略研究点 ,来验证两个相互竞争的劳动经济学中的理论。以 Farber 的研究目的出发,出租车司机的工作环境有两个重要的特点:(1)他们每小时的工资,受一些如天气等因素的影响,每天都可能会变化。(2)他们每天的工作时长随着他们的决定,每天都可能会变化。这些特征引起了一个有趣的问题,每小时工资和工作时长之间的关系是什么?新古典经济主义模型下,预测出租车司机会在小时工资高的时候工作更长时间。然而,行为经济学的模型的预测结果刚好相反:如果司机有一个明确的收入目标——比如每天挣100块——一直干到完成目标,那么他会在小时收入高的时候工作更短的时间。具体的来说,如果你是个有具体目标的司机,你会在生意好的那天(每小时挣25块)干4个小时,而在生意不好的那天(每小时挣20块)干5小时。所以,司机们在每小时工资高的时候(新古典经济主义模型的预测)还是每小时工资低的时候(行为经济学模型的预测结果)会工作更长的时间?
为了回答这个问题,Farber 弄到了纽约市所有出租车2009年到2013年的行车记录,这些数据现在是公开的。数据包括每次行程的起使时间、起使地点、终止时间、终止地点,车费,以及小费(用信用卡付的小费)。用这些出租车的元数据,Farber 发现大多数司机在每小时收入高的时候会工作更长时间,与新古典经济主义理论相同。
除了这个主要发现,用这些数据,Farber 可以更好的理解其中的异质性和动力学原因。他发现,新司机渐渐的学会在生意好的时候多工作几个小时(如新古典主义模型预测的一样)。同时,行为像是有明确目标的新司机,更可能会放弃当司机。这两个微妙的发现,有助于解释当前观察到的司机的行为。只有在这种大数据量的数据集上才可能发现。在早期研究中,使用纸质的行车表单,只有一小部分司机在短时间里的行车记录(Carmerer et al. 1997),是不可能察觉到的。
Farber 的工作很接近使用大数据进行研究的最佳情况,因为政府收集的数据十分接近 Farber 想要收集的数据(一个不同点是 Farber 希望得到总收入——车费加小费——而政府数据只包括了使用信用卡支付的小费)。然而,光有数据是不够的。Farber 的研究的关键在于将一个有趣的问题与这些数据结合。问题的关注点的对实验的影响,超越了实验的具体设置。
第二个数数的例子来自 Gary King, Jennifer Pan, 和 Molly Roberts (2013)的工作,研究中国政府的网上审查制度。然而,这里的研究者需要自己收集数据,而且他们需要解决他们数据的不完整性。
King 和他同事们的动机是:有一个有成千上万人的审查机构在审查中国的社交媒体上的帖子。然而研究者和公众对审查机制并不了解,不清楚审查机构如何决定哪些帖子需要删除。事实上,中国学者对于哪些帖子更容易被删除有不同的预期。一些人认为审查者关注于批判国家的帖子,而另一些认为关注于激励集会行为的帖子,比如抗议游行。弄清哪种预期是正确的,会影响学者对中国和其他从事审查的政府机构的看法。因此,King 和他的同事希望将发布后紧接着就被删除的帖子与发布后从未删除的帖子做比较。
收集这些帖子需要惊艳的工程技巧,这要爬取超过 1000 个中国社交媒体网站——每个页面有不同的布局——发现相关帖子,然后再次访问这些帖子来看哪些在后来被删除了。除了需要面对大规模网络数据爬取的相关的工程学问题,这个项目还要面对另一个挑战,它的爬取速度得很快,因为很多被审查的帖子在24小时以内就被删除了。也就是说,速度慢的爬虫会漏掉很多审查后删除的帖子。更进一步的,这些爬虫还不得不隐蔽的收集帖子,以防社交媒体的网站阻止它访问或者为躲避这项研究而改变审查策略。
当这个巨无霸工程完成时, King 和他的同事收集到了 1100 万个帖子。这些帖子对应到85个不同的主题,这些主题分别假定了敏感性级别。比如,艺术家、异议人士艾未未是个敏感性高的主题;人民币的升值和贬值是个中等敏感性的主题;世界杯是一个低敏感性的主题。这 1100 万个帖子里,大约有 200 万被审查删除了。令人奇怪的是,King 他们发现,对高敏感度的帖子的审查,仅比中和低敏感度帖子略微高一点点。也就是说,中国的审查机构对提到艾未未的帖子的审查程度,与提到世界杯的审查程度差不多。有种观点是政府只审查高敏感度的话题。但 King 的发现并不支持这个观点。
然而,这种按主题计算审查率的简单的计算方式可能具有误导性。例如,政府也许会审查支持艾未未的帖子,但会把批判他的那些留下。为了更仔细的区分这些帖子,研究者需要估计每个帖子的 情感(sentiment)。不幸的是,使用预设字典的方式来自动的估测情感,在多数情况下效果都不是很好(回忆一下 2.3.9 节推测 2001 年的 911 事件中情感变化曲线的研究)。因此,King 他们需要找到一个方法来标记这 1100 万推文,推文是(1)批判国家,(2)支持国家,还是(3)无关的或事实性报道。这看上去工作量很大,但是他们用了一个在数据科学常见,但在社会科学里相对少见的技巧:监督式学习(supervised learning);见图 2.5。
第一步,预处理。将这些推文转换成 文档-词语矩阵(document-term matrix)。每行对应一个文档,每列记录这个推文是否包含某个词(如:抗议或交通)。接着,一组研究助理手工标记一小部分推文的情感倾向。然后,他们用这些手工标记的数据训练一个机器学习模型,模型能够通过推文中出现的词语来推测这条推文的情感倾向。最后,他们用这个模型估计了所有 1100 万帖子的情感倾向。
因此,与其人工的阅读和标记这 1100 万帖子——讲道理这方法不现实——King 他们手工标记了一小部分推文,然后用监督式学习的模型来推测所有帖子的情感倾向。完成这些分析之后,他们得到了一个出人意料的结论,帖子被删除的可能性与帖子是支持还是批判国家无关。
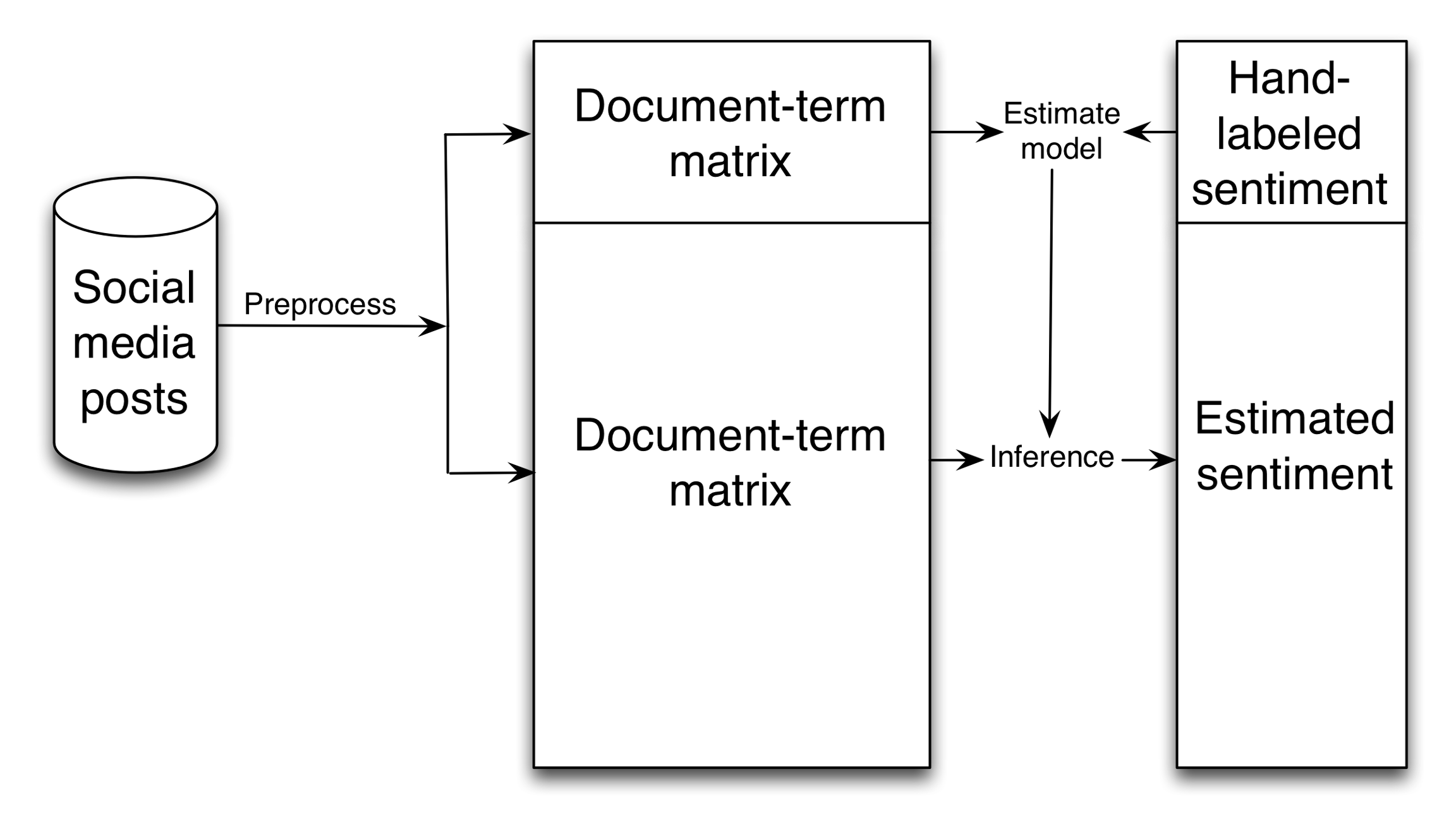
图2.5: King, Pan and Roberts(2013)估计 1100 万中国社交媒体帖子情感倾向的步骤的简化示意图。首先,在预处理步骤,研究者将帖子转为 文档-词语矩阵(document-term matrix)(更多信息见 Grimmer and Stewart(2013))。第二部,手工标记一部分帖子样本的情感倾向。第三步,他们训练了一个监督式学习的分类模型。第四部,他们用这个模型来估计所有帖子的情感倾向。更详细的介绍,见 King, Pan and Roberts (2013)的附录B。
最后,King 他们发现,只有三个主题的帖子是被定期审查的:色情的,批判政府的,以及可能会引起集会活动的(如:可能会引起大规模抗议的)。通过观察大量帖子,看那些被删除了,而哪些没被删除。通过简单的观察与计数,King 他们能够推测政府的审查策略。更进一步的,这铺垫了一个贯穿全书的主题,监督式学习——手工标记一些输出,然后构建一个机器学习模型来标记剩余的部分。这在数据时代的社会学研究中十分常见。你会在第三章 (问问题) 和第五章(大规模协作)中看到与图 2.5 很相似的图。
纽约出租车司机的行为和中国政府对社交媒体的审查行为,这两个例子显示出相对简单的方式——数数,也会做出一些有趣又重要的研究。然而,这两个例子中,研究者需要将有趣的问题与大数据建立联系;数据本身是不够的。
Last updated