
3.4 该问谁
数字时代使得概率抽样难以实施,并且带来了新机遇——非概率抽样。
在抽样的发展历史上,曾有两个相互竞争的抽样方式:概率抽样和非概率抽样。尽管在早期,这两种抽样方式都在使用,但概率抽样站着主导性地位,很多社会学家都被教导,以极大的怀疑态度看待非概率抽样。然而,正如我下面将介绍的,数字时代带来的改变,意味着到了研究者改重现考虑非概率抽样的时候了。特别是概率抽样的越来越难以实现,并且非概率抽样越来越快捷、便宜,效果越来越好。更快和更便宜,意味着可以更频繁的进行调查,以及可以在更大的抽样数量上进行调查。比如说:通过使用非概率抽样的方法,「Cooperative Congressional Election Study (CCES)」对比使用概率抽样大约多 10 倍的调查对象进行测验。这种更大规模的样本,使得政治研究人员可以在各种子分组和社会环境下研究人们的态度和行为。并且,所有这些规模上的增加并没有牺牲估测的质量(Ansolabehere and Rivers 2013)。
目前,「概率抽样」在社会学研究的抽样方法中占主导地位。使用概率抽样时,目标人群中的所有成员都有一个已知的,非零的概率会被抽到。这种条件下,优雅的数学结果为研究人员利用样本推断目标人群提供了可证实的保证。
然而,在真实情况下,很难达到数学证明所需要的条件。比如,覆盖误差和无响应问题。因此,研究人员常常不得不使用各种统计学的调整方法,使得通抽样结果推测目标人群。理论上的「概率抽样」在概率上可以保证结果的有效性,而实际操作中的「概率抽样」常常无法保证,并且依赖各种统计学上的调整。因此,将二者区分开来十分重要。
随着时间的推移,理论上的概率抽样与实际中的概率抽样之间的差异越来越大。比如说,在高质量的,昂贵的调查中,无响应的比例正稳步增加(图 3.5)(National Research Council 2013; B. D. Meyer, Mok, and Sullivan 2015)。在电话推销中,无响应率更高——有时高达 90% (Kohut et al. 2012])。越来越高的无响应比例已经威胁到估测的质量,因为估测结果越来越依赖于校准无响应比例的统计学模型。有些人担心逐步降低的质量和逐渐增高的成本这两个双胞胎,正在威胁着调查型研究的根基(National Research Council 2013)。

图 3.5:无响应比例逐年稳步增加,即使是昂贵的高质量调查(National Research Council 2013; B.D.Meyer, Mork, and Sullivan 2015)。无响应比例在电话推销中更高,有时高达 90% (Kohut et al. 2012。从无响应比例长期趋势上看,数据收集将更昂贵,并且估测结果将更不可靠。节选自 B.D.Meyer, Mok, and Sullivan(2015), 图 1。
在概率抽样日渐式微的同时,非概率抽样方法有了亦可赛艇的进展。非概率抽样的方法有很多种,但它们都有一个共同点,这些方法都不能轻易的适应概率抽样的数学框架(Baker et al. 2013)。也就是说,非概率抽样的方法不能保证每个人都有一个非零的概率被抽到。非概率抽样方法在社会学研究者见的名声很臭。这与一些经典的社会学研究的失败案例有关,比如之前讨论过的「文学文摘」的惨败,以及「Dewey Defeats Truman」(杜威击败杜鲁门),对 1948 年美国大选的错误预测(图 3.6)。
图 3.6:哈里·杜鲁门 总统拿着报纸,头条中错误的宣布了他大选中被击败。这个头条部分机遇一个非概率抽样的结果(Mosteller 1049; Bean 1950; Freedman, Pisani, and Purves 2007)。 尽管「Dewey Defeats Truman」 发生在 1948 年,这已然是研究者对非概率抽样持怀疑态度的主要原因之一。图片来自于:Harry S. Truman Library & Museum。
与数字时代相适应的一种非概率抽样形式是「online panel」(在线小组)。研究者使用的在线小组通常来自小组提供商,例如公司,政府或者大学。提供商们构建的小组有大量的,多样的参与者,他们像提供服务一样作为调查对象参与到调查中。小组的参与者通常是通过各种例如在线广告的临时的方式招募而来。接着,研究者可以向小组提供商购买一些符合他们要求的样本(e.g., nationally representative of adults)。这种在线小组是一种非概率抽样,因为不是每个人都有一个已知的、非零的概率会被抽到。尽管非概率的线上小组已经被社会学研究者(例如,CCES)所使用,对于非概率方法估测的质量,依然存在着一些辩论(Callegaro et al. 2014。
抛开这些辩论,我之所以说到了研究者重新考虑非概率抽样的时候,有两个主要原因。首先,数字时代下很多收集、分析非概率抽样的方法得到了长足发展。这些新的方法与以往那些会引起各种问题的方法有很大的不同,我认为可以把他们看作是「非概率抽样 2.0」。第二个原因是,概率抽样在实践中变得越来越难。当有很高的无响应比例时,就像现在的真实实验情况,调查对象被抽样的概率变得不确定,因此,概率抽样与非概率抽样并不像很多学者相信的那样有大的差异。
正如我之前提到过的,很多学者对非概率抽样持怀疑态度,部分是因为在几个臭名昭著的实验中都使用了非概率抽样。Wei Wang, David Rothschild, Sharad Goel, and Andrew Gelman (2015)的研究工作,可以说明我们在非概率抽样上得到了怎样的发展。他们通过一个毫无疑问的非随机样本——美国的 Xbox 用户,正确的复现出 2012 美国选举的结果。研究者通过 Xbox 游戏来超募调查参与者。正如你所想的,Xbox 的抽样向男性和年轻人倾斜:18 至 29 岁的年轻人在选民中占 19 %,但在 Xbox 的样本里占到了 65 %,男性在选民中占 47 %, 但在 Xbox 的样本中高达 93%(图 3.7)。由于在人口统计学上的严重偏差,Xbox 的原始数据并不是预测选举结果的好指标。他的预测结果是米特·罗姆尼会大胜巴拉克·奥巴马。再次强调,使用未调整的非概率抽样结果是多么的危险,让人回想起「文学文摘」的滑铁卢。
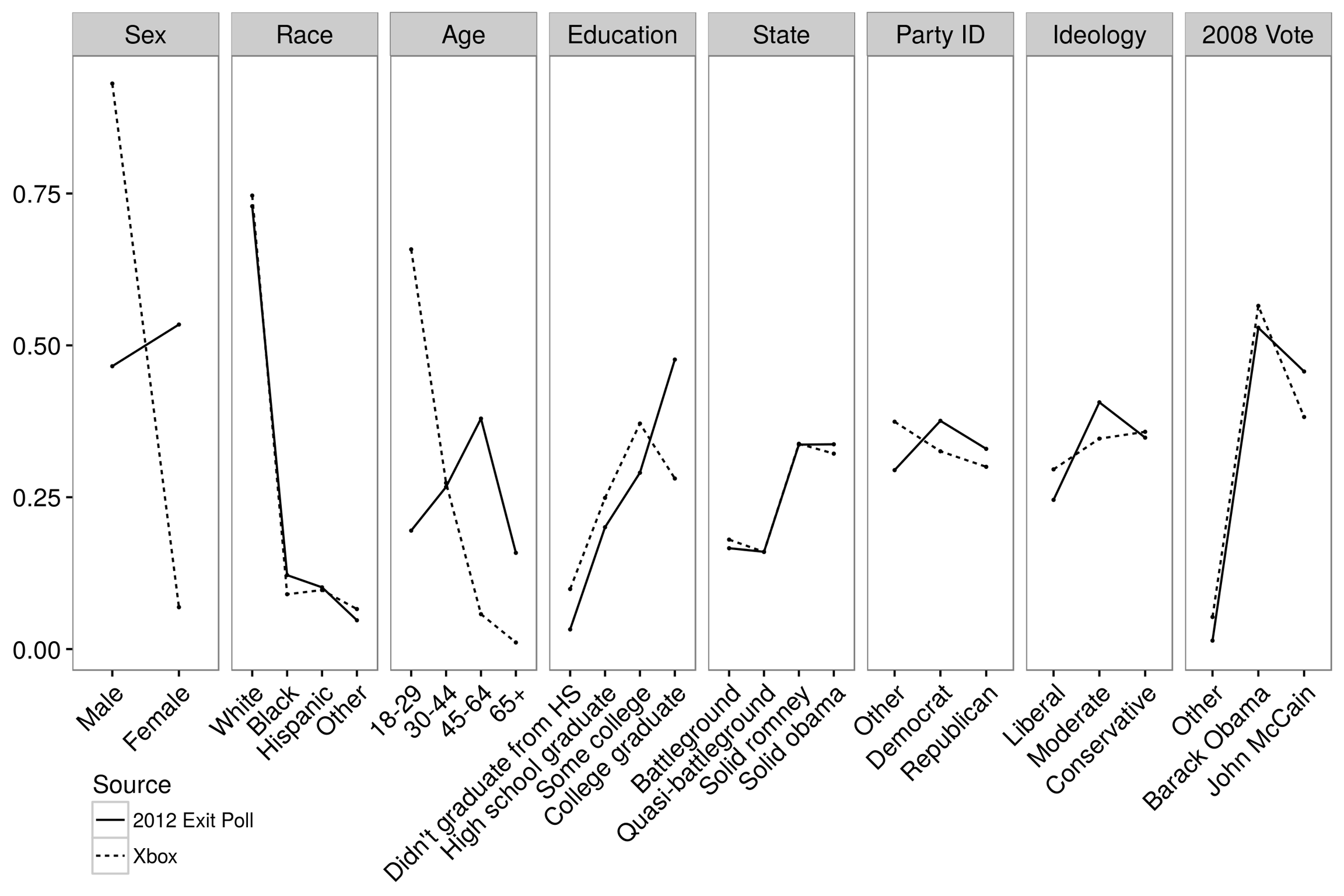
W.Wang et al. (2015) 实验中参与者的人口统计学信息。由于这些参与者是从 Xbox 上招募的,与 2012 大选的选民相比,他们更年轻,男性更多。节选自 W.Wang et al. (2015),图 1。
然而,Wang 他们意识到了这些问题,并尝试用对他们的非概率抽样进行调整。具体的说,他们使用了「post-stratification」(事后分层),一个概率抽样中广泛使用的方法,来调节覆盖误差和无响应问题。
事后分层的主要思想是,使用目标人群的辅助信息来提升从样本中得出预测的效果。在用事后分层来调节非概率抽样的预测结果时,Wang 他们将样本切成几个不同的组,对每个组来估计对奥巴马的支持率,然后对这些组的结果进行加权平均,来得到总体的预测结果。举例来说,他们可以将样本分为两组,男性和女性。分别预测男性和女性对奥巴马的支持率。通过选民中有 53% 的女性,47% 的男性,对预测结果进行加权平均,来得到总体预测结果。简单的说,通过真实情况的各组占比信息,事后分层对不平衡样本进行了修正。
事后分层的关键是构建正确的组别。如果你可以将样本分为均质组,就是说同组的参与者的偏好相同,那么时候分子就可以得到无偏差的估计。具体的来说,如果你通过性别对样本进行事后分层,如果所有的男性有相同的反馈偏好,同时所有的女性也有相同的反馈偏好,那么得到的估测就是无偏见的。这个假设称作「homogeneous-response-propensities-within-groups」假设,我会在本章末的数学原理简介中进行更详细的介绍。
显然地,所有的男性和所有的女性似乎未必有相同的反馈偏好。然而,当组别越多的时候,「homogeneous-response-prepensities-within-groups」假设会变得更合理。大致来说,如果你分更多的组,组内人群的均质性就更容易实现。比如,也许所有的女性都有相同的反馈偏好并不合理,但所有年龄在 18-29 岁,大学毕业的,生活在加利福尼亚的女性有相同偏好会更合理些。因此,随着分组数量的增加,事后分层所需要的假设就变得更合理。在这个基础上,研究者在使用事后分层时常常希望建立巨量的分组。然而,随着分组数量增加,研究者会遇到另一个问题:数据稀疏性。如果组内只有很少的人,那么估测结果的不确定性就会增大,当极端情况时,如果分组内没有一个调查对象,那么事后分层就 GG 了。
解决「homogeneous-response-prepensities-within-groups」假设的合理性与保持每组有合理样本数的矛盾的方法有两个。第一个方法,研究者可以收集更多的,更多样化的样本,这可以确保每组有一个合理的样本大小。第二个方法,可以使用更复杂的统计学模型来对每组进行预测。事实上,有时研究者会同时使用这两个方法,Wang 他们在重现选举结果的研究中对 Xbox 的参与者就使用同时使用了这两个方法。
因为他们使用非概率抽样方法和计算机执行的访谈(我会在 3.5 节介绍更多 computer-administered interview),Wang 他们收集数据的价格极其低廉,使得他们收集到了 345,858 个不同参与者的信息,这对于标准的选举投票来说是一个巨大的数字。巨量的样本使他们在使用事后分层时可以构建大量组别。虽然事后分层通常将样本分为上百个组,Wang 他们以性别(2 组),种族(4 组),年龄(4 组),教育程度(4 组),所在的州(51 组),支持的政党类别(3 组),政治倾向(3 组),以及 2008 年的投票情况(3 组),将样本分为了 176,256 个组。也就是说,得益于低价格的数据手机,他们使得整个方法所需的假设更合理。
即使有 345,858 个不同的参与者,Wang 他们的分组里还是有很多组几乎没有人。因此,他们使用了叫做「multilevel regression」(多级回归)的方法来估测每个组所支持的政党。具体的来说,为了估测某个组对奥巴马的支持度,多级回归 会从很多相近的关联组里抽取信息。比如,假设我们要对拉美裔人年龄在 18 到 29 岁之间的,大学毕业的,登记为民主党的,自认为是温和派的,在 2008 年对奥巴马投支持票的女性,估测他们对奥巴马的支持情况。这是个非常非常具体的组,很可能没有一个样本属于这个组别。因此,为了对这个组进行估测,多级回归使用统计学模型,联合很多相似组别的人的信息来进行估测。
因此,Wang 他们使用的方法结合了多级回归和事后分层,所以他们称作「multilevel regression with post-stratification」。或者更亲切的称作「Mr.P.」。当 Wang 他们用 Mr.P. 来从 Xbox 的非概率抽样进行预测时,他们得到的预测结果与 2012 年选举时奥巴马真实的总体支持情况非常接近(图 3.8)。事实上,他们的预测结果比传统民意调查的聚合结果还要准确。因此,这个例子中,统计学的调整——准确的说是 Mr.P.——似乎成果的消除了非概率样本的偏见;如果你查看未调节过的 Xbox 用户数据,样本存在的偏见显而易见。

图 3.8:W.Wang et al. (2015) 的估测结果。使用未调节的 Xbox 样本,估测结果并不准确。但是,对样本的权重进行调节后的预测结果,比传统的基于概率的电话调查的瓶蕨结果还要准确。节选自 W.Wang et al. (2015),图 3 和图 4 。
Wang 他们的研究对我们主要有两个教训。首先,未调节的非概率抽样会导致不准确的预测结果;这个教训很多研究者之前已经听过。然而,第二个教训,是非概率抽样,在经过合适的分析后,可以得到良好的估测结果;非概率抽样本身不会自动导致类似「文学文摘」的失败。
在概率抽样与非概率抽样之间进行选择依然很艰难。有时研究者希望有遵循要个的规则(例如,常常使用概率抽样),但提出这样的规则越来越难。研究者面对着实践可行性与假设合理性之间艰难抉择。概率抽样的成本越来越高,并且离理论结果也越来越远。而非概率抽样虽然便宜快捷,但研究者不太熟悉,并且种类繁多。但有一件事情是明确的。如果你不得不使用非概率抽样,或者你的大数据资源缺乏代表性(回忆一下第二章),那么我们有很强的理由相信,使用事后分层以及其他相关技术进行估测的结果,要好过未调节的、原始的预测结果。
Last updated