
3.3 整体性调查误差框架
整体性调查误差 = 表征误差 + 测量误差
从抽样调查中得到的估测结果常常不是很准。这是说,抽样调查(如估计某校学生的平均身高)得到的结果与观测人口的真实值常常存在差异(该校学生的实际平均身高)。有时这个误差很小,但有时,这个误差很大并且跟很重要。为了理解,测量,并减少这个误差,研究者对抽样调查中可能存在的误差,逐渐构建了一个独立的,统领性的概念框架:「total survey error framework」(Groves and Lyberg 2010)。尽管这个框架从 1940 年代就开始形成,我认为,它依然为我们对数字时代的调查型研究提供了两个有用的思想。
首先,整体性调查误差框架指出,主要有两种误差:bias(偏差)和 variance (方差)。大体上说,bias 是系统性误差,variance 是随机性误差。举例来说,假象进行 1,000 次重复的抽样调查,然后看一看这 1,000 次调查结果的分布情况。Bias 就是这些重复调查估测的平均值与真实值的差。Variance 是这些估测的变化程度。如果其他都一样,我们会倾向于选择一个没有误差,方差很小的调查方式。不幸的是,对于很多实际问题,这种无误差、小方差的估测方式是不存在的。这将研究者推向一个尴尬的位置,必须在偏差与方差之间进行权衡。有些研究人员本能的倾向于无偏差的方式,但一股脑的关注于偏差会导致错误的结果。如果研究的目标是给出一个经可能与真实值接近的估测,那你最好选择一个有小偏差小方差的方式,而不是选择一个无偏差大方差的方式 (图 3.1)。也就是说,整体性调查误差框架指出,当评价一个调查型研究的方法时,我们最好同时考虑偏差与误差。
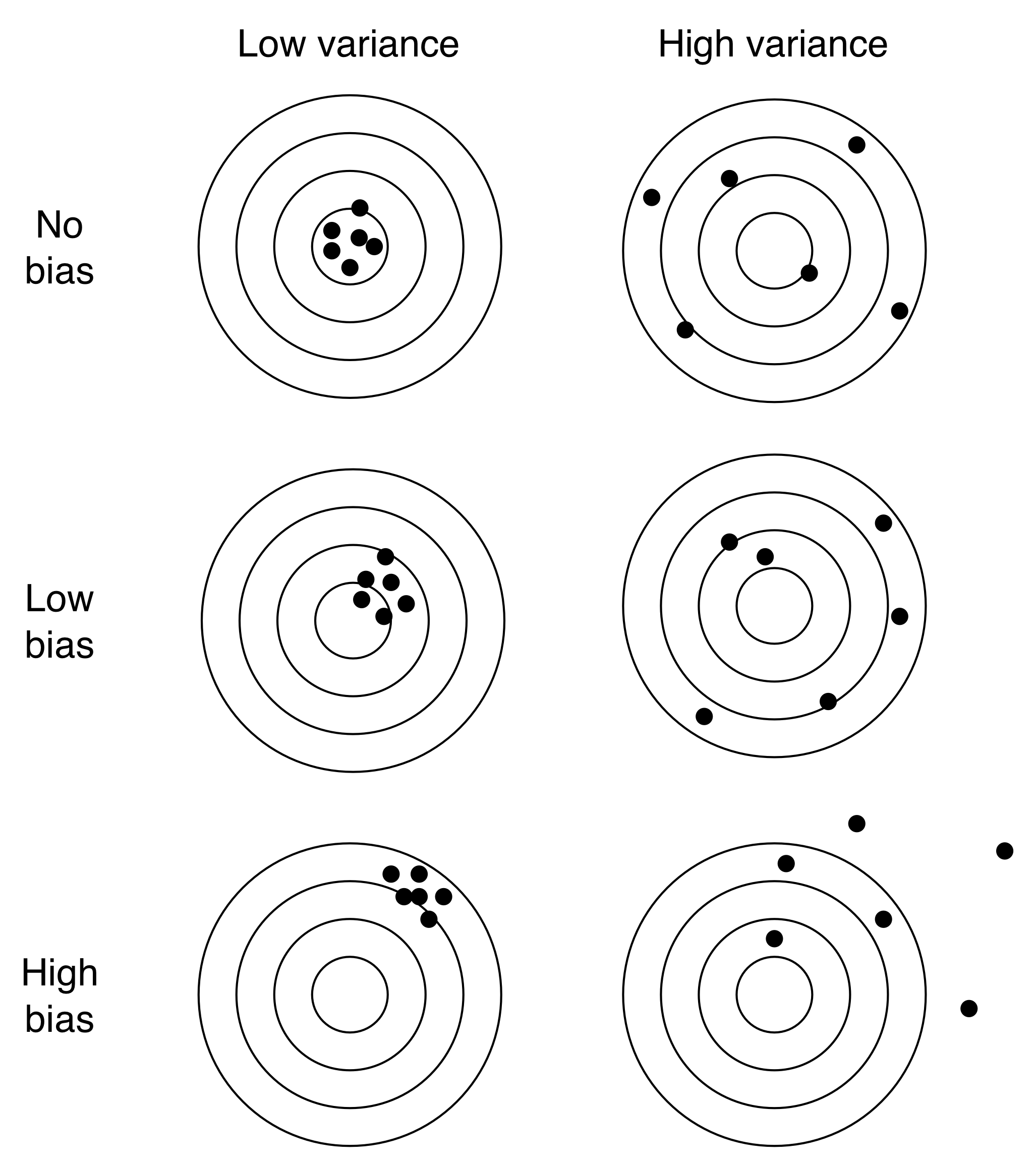
图 3.1: bias(偏差)和 variance (方差)。理想情况下,研究人员希望有一个无偏差、低方差的估计方式。但实际上,他们常常需要在偏差和方差之间权衡。尽管有些研究人员本能的倾向于无偏差的方式,但有时低偏差、低方差的方法会得到更准确的估计。
其次,整体性误差框架告诉我们,误差来源主要有两种:访谈人群(代表性)以及对访谈内容的评估(衡量标准)。比如说,我们想估测一下法国公民对网络隐私的态度。进行这项估计有两个难点,首先,从被试提供的答案中,你需要推测出他们对网络隐私的态度,这个问题与衡量标准有关。其次,从被试们的答案推测得到的态度中,你还得将这些态度推广到问题研究的人群中去,这与代表性有关。代表性「representation」与衡量标准「measurement」,这两部分将贯穿本章。完美的抽样与辣鸡的问卷,会得到一个辣鸡的估测结果。同样的,辣鸡的抽样与完美的问卷也是如此。也就是说,一个良好的估测需要合理的表征方式与衡量标准。考虑到这些问题,接下来我将回顾研究者们在代表性与衡量标准上的一些思考。接着,展示一下这些思想是如何指导数字时代的调查型研究的。
Last updated