
2.4.3 模拟实验
对于没有做过或不能进行的实验,我们可以模拟实验。从大数据时代受益最多的两种模拟实验的方式是「自然实验」( natural experiments )和「匹配」( matching )。
一些重要的科学和政策问题是因果关系。例如,工作培训对收入有怎样的影响?一些研究者尝试回答这个问题,可能会想比较一下参加培训和没参加培训的人收入。但是这些收入差距有多少是因为参加培训,而有多少是因为这两群人之间原本就存在的不同。这个问题很棘手,而且并不会因为有了更多的数据就自然而然的解决了。也就是说,无论数据量有多大,都要考虑样本中原本存在的差异(preexisting differences)。
在很多时候,估计某些操作的因果效应,最理想的方式是进行「随机对照实验」( randomized controlled experiment )。随机找两组人,研究者让一组人参加实验,另一组做对照组。第四章会详细讨论「实验」,这里关注使用「非实验数据」的两种策略。第一种策略是寻找在现实世界里随机安排给某些人,而另一些人不安排的任务。第二种策略是通过统计的校准方法 (statistically adjusting),解释「非实验数据」的样本之间原本存在的差异。
怀疑论者也许会说这两种策略都不可取,因为它们都有很强的假设。这些假设很难被检验,而且实际情况经常会违法这些假设。我很同情他们,但我们可以看的更远一些。通过「非实验数据」估计因果效应确实很困难,但并不是说没有尝试的价值。例如,一些实验因为逻辑上的限制而不能进行实验,或者因为道德上的限制人们不愿意进行实验,这时就有了非实验方式的用武之地。或者,非实验的方式可以从已有数据中获取一些指导性意见,帮助设计「随机对照实验」。
在开始之前,同样值得注意的是,因果关系推测是社会学研究中最复杂的课题之一,并且它也会引起激烈的情绪化的争论。为了帮你建立对这些方法直觉感受,下面我从积极的角度介绍每种方法以及使用这种方法会面临的挑战。每种方法更详细的介绍可以在章节末尾的扩展材料找到。如果你计划在你的实验中采用其中的策略,我强烈推荐读一读关于因果推测的优秀书籍中的一本(Imbens and Rubin 2015; Pearl 2009; Morgan and Winship 2014)。
现实世界里,有些时候会随机安排某种任务给一些人。使用这种事件的「非实验数据」可以推测因果关系。这种方式叫做「自然实验」。「自然实验」中最直观的一个例子是 Joshua Angrist ( 1990 )的研究,他希望衡量服兵役对收入的影响。在越南战争期间,美国通过草案扩大了军队规模。为了决定征召哪些人服役,美国政府进行了一次抽签活动。将所有的日期分别写在纸片上,如图 2.7 那样,每次抽出一张,来选出一个出生日期,以此决定征召哪些年轻人来服役(草案中的参选人群不包括年轻女性)。根据抽签结果,在 9 月 14 日出生的男性首先被征召,第二批服役的是 4 月 24日出生的,以此类推。最终,抽出了 195 个不同的日期,生日在这些日期中的男性将被征召,而生日在另外 171 天中的人不用服兵役。

图 2.7 : 国会议员 Alexander Pirnie (R-NY) 抽出第一个胶囊,1969 年 12 月 1 日,义务兵役草案。Joshua Angrist (1990)将彩票草案与「社会保障局」的收入数据结合,以估计兵役对收入的影响。这是使用「自然实验」的一个研究的例子。 图片来源: 美国兵役登记局 (1969)/ Wikimedia Commons。
{kind=link}
乍看上去也许并不明显,彩票草案与「随机对照实验」有个关键的相似点:在这两种情况下,参与者都被随机分派了某个任务。为了研究这些随机分派任务的影响,Angrist 利用了 always-on 的大数据系统:美国社会保障局。这个系统收集了几乎所有美国人的就业收入信息。政府行政记录中记录了哪些人在彩票草案中被抽中,Angrist 将收入信息与中签记录结合,他发现退伍兵的收入比未服役过的人低 15 %。
如同上面的例子中,某些社会,政策或自然因素强制分派的任务可以被研究者们利用,并且有时这些任务的影响会被大数据系统记录下来。这个研究策略可以总结为下面这个公式:
random(orasifrandom)variation+always-ondata=naturalexperiment
随机(或近似随机)变化+实时数据=自然实验
举一个在数据时代使用这个策略的例子,Alexandre Mas 和 Enrico Moretti (2009) 试图评估与有工作效率高的同事一起工作对工人生产力的影响。在揭晓答案之前,需要注意的是,你也许会有两个相互矛盾的预期结果。一方面,你可能会想,与工作高效的人一起工作会提高其他工人的生产力,因为会有来自同事的压力。或者,另一方面,你可能会想工作努力的人会使得他的同事们变懒惰,因为无论如何都会有人替他们完成工作。研究同事带来的影响,最直观的方法是进行「随机对照实验」,给员工随机分配工作效率等级不同的同事,然后评估所有人的生产力。然而,研究者并不能控制任何企业的排班。所以 Mas 和 Moretti 不得不依赖「自然实验」——超市中收银员的轮班。
在 Mas 他们选择的超市中,由于轮班以及班次的重叠,每个收银员在一天中不同的时候一起工作的人也不同。并且,这个超市里收银员收到的任务与他们的工作效率或超市的繁忙程度都无关。也就是说,尽管收银员的轮班不是由抽签决定的,但员工们几乎随机的与工作效率高(或低)的同事一起工作。幸运的是,这家超市还有一个数字时代的结账系统,跟踪每个收银员扫描过的所有物品。使用结账系统的日志数据,Mas 和 Moretti 可以对每个员工进行精确的实时的生产力测量:每秒扫描的物品数。结合轮班的「随机变化」与每秒扫描的物品「实时数据」,Mas 和 Moretti 和估测出如果同事的生产力比平均值高 10%,会使得员工他自己的生产力提高 1.5% 。更进一步,Mas 他们利用这些大量丰富的数据探索了两个重要的问题:这种影响的 异质性(heterogeneity)——哪种员工更容易被影响?以及这种影响背后的 机制(mechanisms)——为什么与生产力高的人工作会提高他自己的生产力?我将在第四章种详细讨论这两个问题。
从上面两个研究推广一下,这些研究有相同的策略:使用「实时数据」来测量某些「随机变化」的影响。表 2.3 总结了一些使用这个策略的研究。在实践中,研究者们使用两种不同的途径来发现「自然实验」,这两种途径都可以发现丰硕的成果。一些研究者从「实时数据」出发,来寻找生活中有「随机变化」的事件;其他一些从有「随机变化」的事件出发,寻找可以捕捉影响效果的「实时数据」。
表 2.3 :大数据与「自然实验」结合的例子
具体的关注点
「自然实验」
「实时数据」
文献引索
到目前为止,在关于「自然实验」的讨论中我遗漏了重要的一点:从自然事件中推得你想要的,这个过程有时相当微妙(tricky)。让我们回想一下抽签征兵的例子。在这个研究中,Angrist 关注于估测服兵役对收入的影响。不幸的是,即使抽签是随机的,兵役并不是随机分派的。不是所有被抽到的人都去服役了(因为有多种豁免情况),并且不是所有服役的人都是征召入伍(有些人是志愿服役)。因为抽签是随机的,研究者可以估测中签对个人的影响。但 Angrist 并不想知道中签有什么影响,他希望知道服兵役对人的影响。然而,为了估测这个影响需要额外的假设。首先假设中签对收入的唯一影响方式是服兵役,这称作 「排外约束」(exclusion restriction)。这个假设可能是错误的,例如,中签的人为了躲避服役选择留在学校继续学习,或者雇主不太喜欢招聘服过兵役的人。一般来讲,「排外约束」是个至关重要的假设,并且通常很难验证这个假设。即便「排外约束」是正确的,研究者仍然无法给所有服兵役的人估测服役的影响,而只能给「依从者」(compliers) 进行估测。然而「依从者」并不是最初希望观测的人群。需要注意,在相对简单的「彩票草案」中依然存在。当对人群的干预不是通过抽签的时候,会引起更多的问题。例如,在 Mas 和 Moretti 对收银员的研究中需要额外假设轮班是随机的。如果这个假设被严重违反,可能会对估测带来误差。总的来说,「自然实验」是一个强有力的策略,来从「非实验数据」中估测因果效应,同时大数据增强了我们利用「自然实验」的能力。然而,使用「自然实验」来估计你想要的关系,需要十分谨慎,有时还需要强约束的前提假设。
接下来我将介绍用「非实验数据」研究因果效应的第二个策略。就是使用统计的校准方式 (statistically adjusting),试图解释接受与未接受干预的人之间原本存在的不同 (preexisting differences)。有很多校准方法,但我会重点介绍 「匹配」 (matching),就是在「非实验数据」中寻找各方面都相同但一个接受了但另一个没有接受干预的样本对。在匹配的过程中,研究者也在「剪枝」 (pruning),就是忽略没有匹配到样本对的情景。因此,这种方法更准确的叫法应该是:「匹配-剪枝法」(matching-and-pruning),但我仍然采用传统的叫法:「匹配」 (matching)。
举个展现「匹配」强劲效果的例子。Liran Einav 与同事们 (2015) 使用「非实验数据」来研究消费行为。他们对 eBay 上的拍卖很感兴趣。下面我将重点介绍起拍价对成交价、流拍率等拍卖结果的影响。
评估起拍价对成交价的影响,最傻瓜的方式应该是直接计算不同起拍价的拍卖成交价。 这适用于通过起拍价预测拍卖的成交价。但如果你关注于起拍价所产生的影响,这种方法就不太适用。因为这不是公平的比较。起拍价低的往往与起拍价高的拍卖很多不同点(例如也许他们拍卖是不同的商品或者卖家不同)。
如果你已经意识到了通过「非实验数据」评估因果效应中存在的问题,你也许会直接跳过上面的傻瓜方式,而考虑进行一个「现场实验」(field experiment)。可以考虑一个具体的物品,例如高尔夫球杆,并且设定一些具体的拍卖参数,例如免运费,以及拍卖持续两周,然后给这些物品设置随机的起拍价。通过比较成交结果,这个实验可以为起拍价对成交价的影响提供非常清晰的测量指标。但这些指标只能应用在一个具体的商品以及一组具体的拍卖参数上。如果换一个商品,结果也许会不同。没有坚实的理论,很难将以此实验的结果推广到其他实验中。更进一步的,「现场实验」非常昂贵,不可能将所有你想尝试的实验都进行一次。
与傻瓜方式和「现场实验」相比,Einav 和他的同事们转向了第三种方式:「匹配」。他们的方法中,主要的技巧是在 eBay 上寻找那些与「现场实验」相似的事件。例如,图 2.8展示了同种高尔夫球杆——「Taylormade Burner 09 Driver」,并且也是同一个卖家——「budgetgolfer」的一部分拍卖。然而,这 31 词拍卖有细微的不同,例如起拍价,结束时间,以及运费。也就是说,这就像是「budgetgolfer」正在为研究者进行实验。
「budgetgolfer」拍卖的这些「Taylormade Burner 09 Driver」就是一组匹配的物品。这些拍卖虽有一些细微的不同,但都是相同的物品相同的卖家。在 eBay 的巨量日志中,有数百万这种物品,每组匹配到的物品里都有成百上千个拍卖纪录。因此,与其比较所有的拍卖交易,Einav 他们在匹配到的物品集里进行比较。为了一起比较这数百万商品,Einav 他们用 「标准价格」(reference value) 重新表示物品的起拍价和成交价。举例来说,如果「Taylormade Burner 09 Driver」的「标准价格」是 100 元 (基于正常售价),10 元的起拍价就用 0.1 来表示,最终售价 120 元,就用 1.2 来表示。

图 2.8: 一个匹配的物品集。 这是同一个卖家「budgetgolfer」拍卖的一种高尔夫球杆「Taylormade Burner 09 Driver」,但在不同的条件下,如不同的起拍价,成交价格有些不同。图片来自 Einav et al.(2015), figure 1b。
记得 Einav 他们关注于起始价对拍卖结果的影响。首先,他们用线性回归估测发现,如果拍卖成功,更高起拍价会使得成交价也越高。他们发现这个平均了所有物品的线性关系,解释起来没有意思。所以,接下来他们用这些巨量数据构建了更精妙的评估。举个例子,分开看不同的起拍价格,不同的起拍价对成交价的影响不是线性的(图 2.9)。具体的来说,对于起拍价在 0.05 与 0.85 之间时,对成交价只有一丢丢影响,这个发现在他们第一次的分析中完全漏掉了。更进一步,与其平均所有物品,Einav 估测了 23 个不同种类物品的起拍价的影响(如,宠物用品,电器以及运动纪念品)(图 2.10)。他们发现,特色鲜明的物品(如纪念品)的起拍价对成交概率影响很小,但对成交价格有很大的影响。但更普通的商品(如DVD光碟)的起拍价对成交价几乎没有影响。也就是说,对所有物品的平均,隐藏了不同商品间起拍价影响成交结果的差异性。
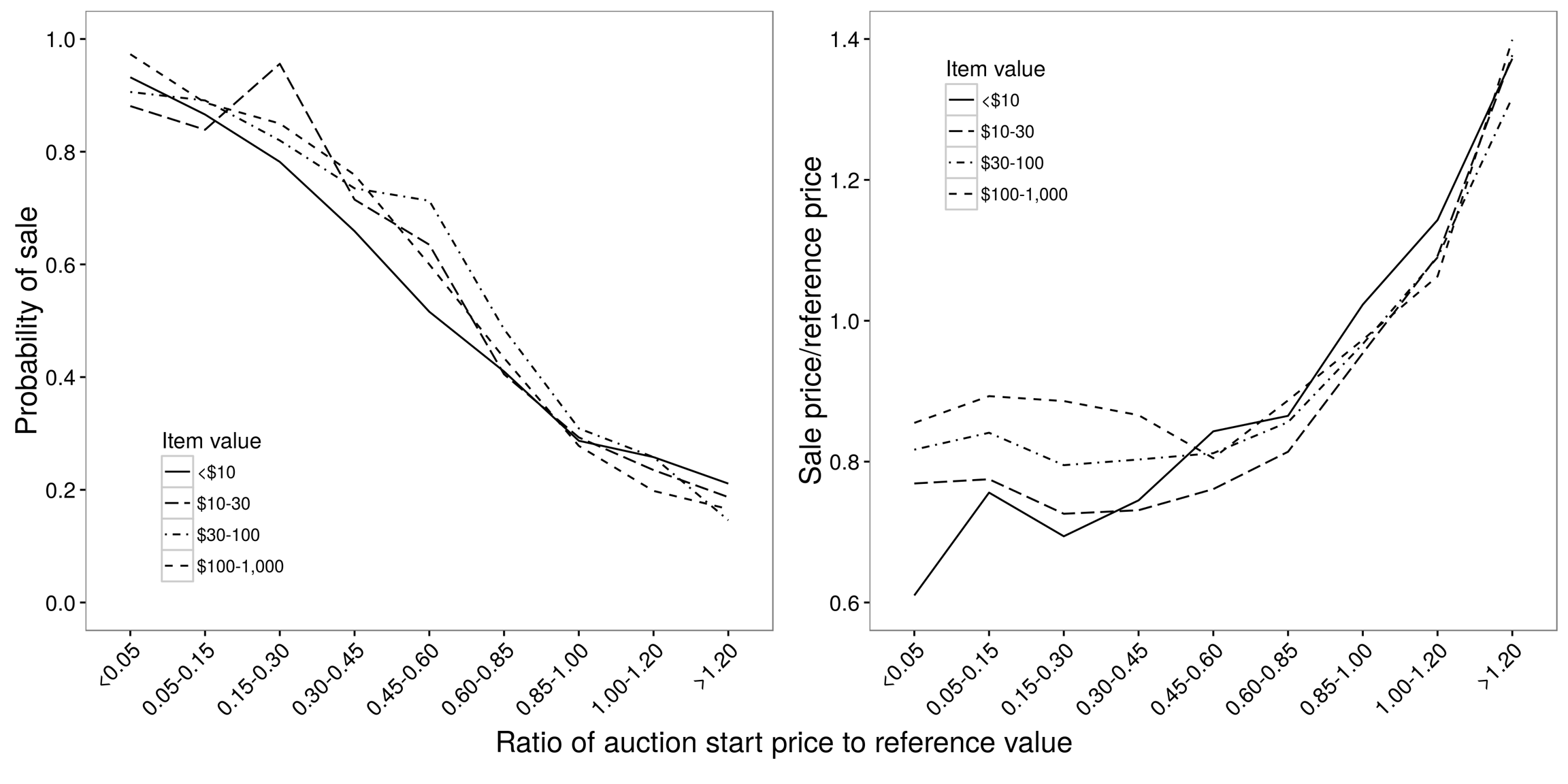
图 2.9:(a)起拍价与成交概率的关系,(b)成交价与成交价的关系。起拍价与成交概率基本上是线性关系,但与成交价之间是非线性关系。其售价在 0.05 到 0.85之间时,对成交价的影响非常小。这两个关系与物品售价无关。图片来自 Einav et al. (2015), figures 4a and 4b。
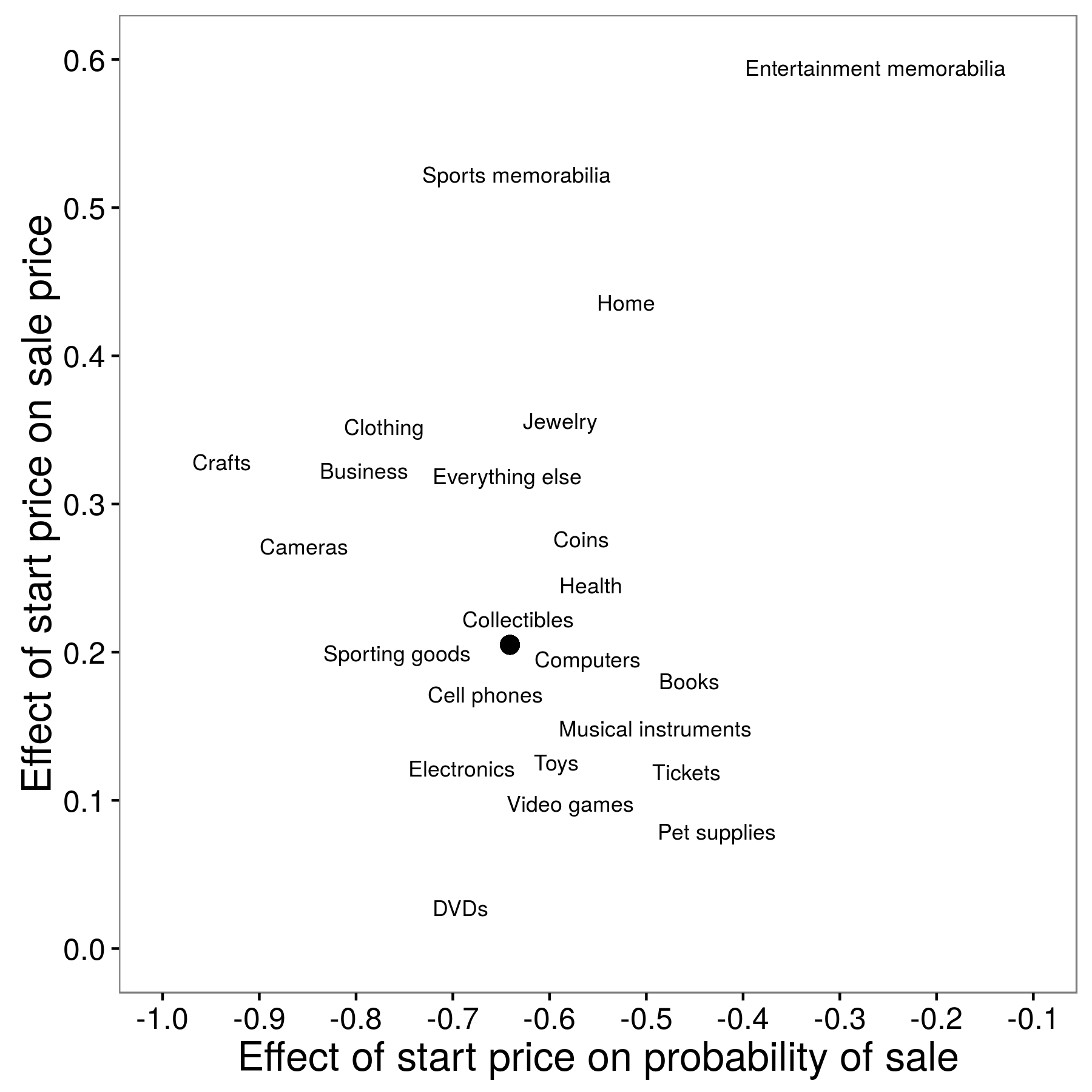
图 2.10:对各类物品的预测。实心点是将所有物品放在一起,得到的平均点 (Einav et al. 2015)。从图可以看出,特色越鲜明的物品(如纪念品)的起始价对成交概率的影响( X 轴)的影响越小,对成交价格( Y 轴)的影响越大。图片来自 Einav et al.(2015), figure 8。
即使你对 eBay 上的拍卖并没有什么兴趣,与结合多种不同物品的线性关系相比,图 2.9 和 图 2.10 提供了更丰富的理解。进一步来说,即使理论上通过「现场实验」可以进行更精妙的评估,实验的成本也高的离谱。
利用「自然实验」的「匹配」方法,有很多情况会导致估测很辣鸡。我认为最大的隐患就是匹配条件,如果溜掉了一些关键的条件会导致有偏差的估测。举例来说,Einav 他们很多的结果,是通过匹配这四个条件:seller ID number, item category, item title, and subtitle。如果物品在的没用做匹配的字段中存在差异,这就会导致不公平的比较。比如说,如果「budgetgolfer」在高尔夫的淡季(比如冬天)调低了「Taylormade Burner 09 Driver」球杆的价格,那么用上面那四个条件匹配,就会得出低起拍价导致低成交价的结论,但实际只是季节上的需求变化。一个解决办法是尝试多种不同的「匹配」。举例来说,Einav 他们使用不同时间间隔,比如一年内的、一月内的、同时的,「匹配」了很多次。幸运的是,他们发现在所有时间窗口都有相似的结果。更进一步的考虑是「匹配」的可解释性。从「匹配」估测出的规律只适用于那些在匹配集的数据,对不满足匹配条件的数据并不适用。例如,Einav 他们的研究中只关注有多个成交记录的物品,也就是专职或半专业的卖家。因此,当解释他们发现的规律时,要记得只能应用在 eBay 的一部分商家身上。
「匹配」是一个使用「非实验数据」的强力策略。对于很多社会学家来说,「匹配」是除了实验的最好方式,尽管他们相信「匹配」还可以继续改进一些。当(1)异质性(heterogeneity) 的影响很重要,(2)用作匹配条件的特征经过了检验时,使用大数据进行「匹配」的效果比小数量的「现场实验」效果更好。表 2.4 列举了一些使用大数据「匹配」的例子。
表 2.4 :一些使用大数据和「匹配」的研究。
具体的关注点
数据来源
文献引索
总的来说,使用「非实验数据」推测因果效应是很困难的,但可以利用如「自然实验」和统计的校准方法(如「匹配」)。在某些情况下,通过这些方法得到的结果会很辣鸡。但如果谨慎的使用,这可以对「实验」进行很好的补充。我会在第四章讨论「实验」。值得注意的是,这两个方法从实时大数据系统中受益匪浅。
Last updated